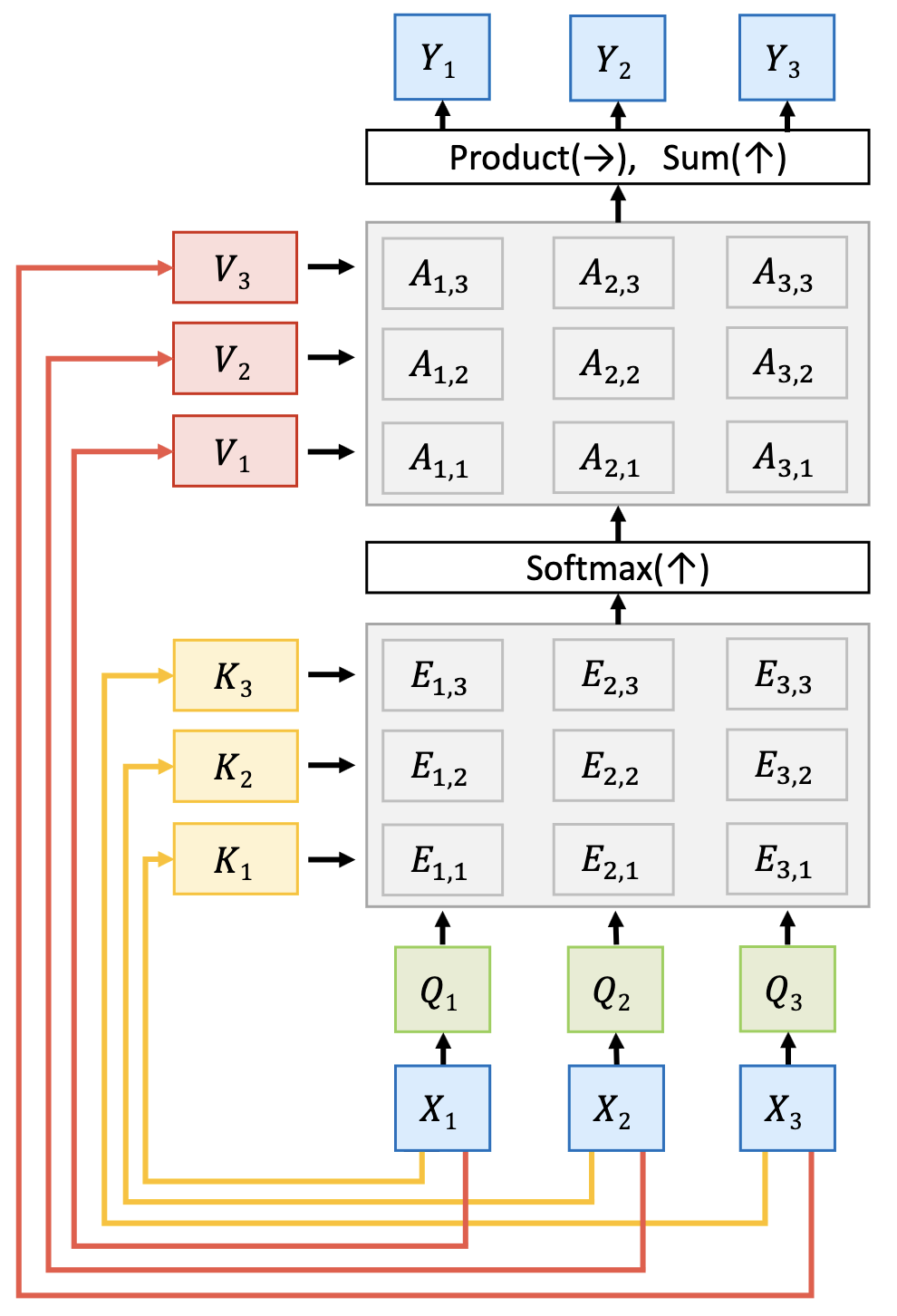
Self-Attention Layer
Inputs:
- Input Vectors:
- Query Matrix:
- Key Matrix:
- Value Matrix:
Computation:
- Query Vectors:
- Key Vectors:
- Similarities:
- Attention Weights:
- Value Vectors:
Permuting
If you permute your input vectors, the queries will have different positions. Same for the rest of the layer.
For instance if the input vectors are in order the query vectors will be in order , same for the output vectors.
Positional Encoding
Self-attention layer doesn’t know the order of the vectors being processed.
In order to make it position-aware, concatenate the input with positional encodings. can be a learnable lookup table or a fixed function.
Masked Self-Attention Layer
Problem: For language modeling, you should only predict the next word using the previous words.
Solution: Set the future words to negative infinity, this will mask the output vectors.
Transformer Block
The transformer block is effectively the following: Properties:
- Self-attention is the only interaction between vectors
- Highly scalable, highly parallelizable
A transformer is a sequence of transformer blocks. In “Attention Is All You Need” they use 12 blocks, D = 512.
![]()
Multi-Head Attention
In real world applications, you don’t perform Self-Attention once. You perform Attention for multiple versions of (with different values) and perform the operations multiple times. This is called Multi-Head Attention.
The goal of this is to handle various input sequences in various ways.