Gradient Descent
Optimization in Machine Learning
Many machine learning problems can be cast into a numerical optimization problem in the form of: is a loss function that measures the model’s performance
How do you find the global minimum? Sadly with a first order derivative you cannot always find the global minimum.
Finding the Best Weights
Think of a ball on a complicated hilly terrain. You can roll the ball down and find a minimum, but how do you find the bottom of the deepest valley?

See this drawing, you may be able to find the deepest valley if you roll from A, but if you roll from B you may not find it. In machine learning initial conditions are extremely important to achieving the least loss.
How to “Roll Down”
Assume the current weight is and we take a step of size in the direction of .
What is the best direction to step? We want to pick that makes as small as possible.
The negative Gradient Direction is the fastest Way to Roll Down
We want that maximizes
We can approximate :
- The Taylor series expansion at the point , and then evaluate the function at point .
- Recap for Taylor Series:
-
- can be approximated out because the higher order terms are extremely small.
- v has to be in the opposite direction of a gradient. Think about two vectors, what direction creates the greatest output for a dot product? It’s when the vectors are in the same direction. Therefore v must be opposite of the gradient.
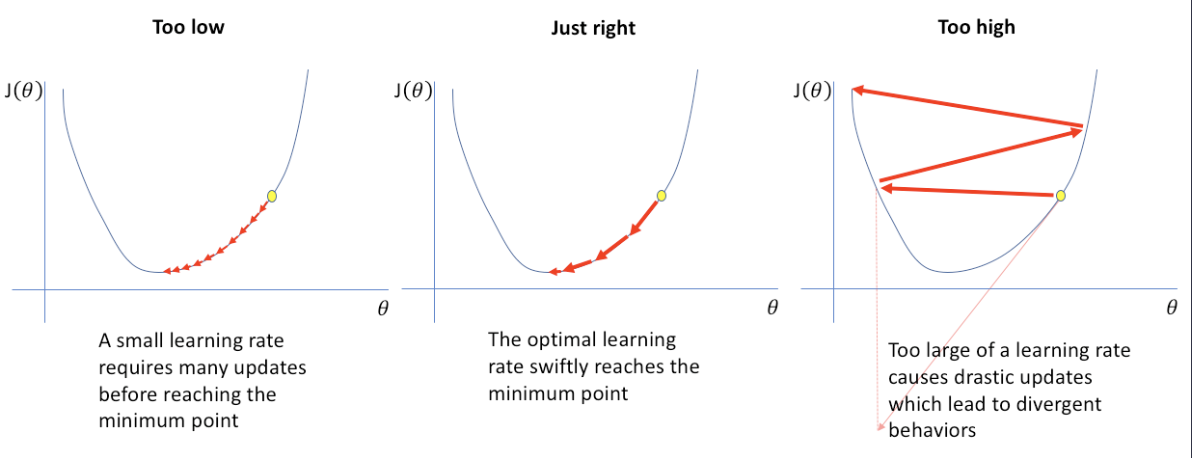
Step Size
Step size cannot be too small or too big. It can be very tricky to set the right step size.
Gradient Descent Algorithm
- Initialize at step
- for do
- Compute the negative gradient direction:
- Update the parameters:
- Iterate until “It is time to stop”
- end for
- Return final parameter weights
Stochastic Gradient Descent
- Instead of using traditional gradient descent, pick a random data point / batch of data points for calculating the gradient.
- When the batch size equals 𝑁, it becomes gradient descent
- This is useful when 𝑁 is large, loading all data in the memory becomes
infeasible - All modern deep learning training uses SGD
- Will be more spikey