Simple Nonlinear Prediction
The “shallow” approach: nonlinear feature transformation (often by hand), followed by a linear classifier
Cons:
- The design of a good feature transformation can be tricky
- The number of new features
Multi-layer Neural Network
The deep approach: stack multiple layers of linear transformations interspersed with nonlinearity
Two layer neural network:
For an N layer neural network:
Nonlinearity
Sigmoid:
- Historically very popular
- Squashes numbers to range
- Saturated neurons “kill” the gradients
Sigmoid:
- Squashes to range
- Still kills gradients
Relu:
- Does not saturate (in + region)
- Very little computation
- What is the gradient when
- MOST POPULAR
Leakey Relu:
- Neuron will not die
- In practice, use Relu on your first try.
Why We Need a Nonlinear Function
If there is no nonlinearity, no matter how many layers you stack, you will still be modeling a linear relationship.
Proof by Example (XOR)
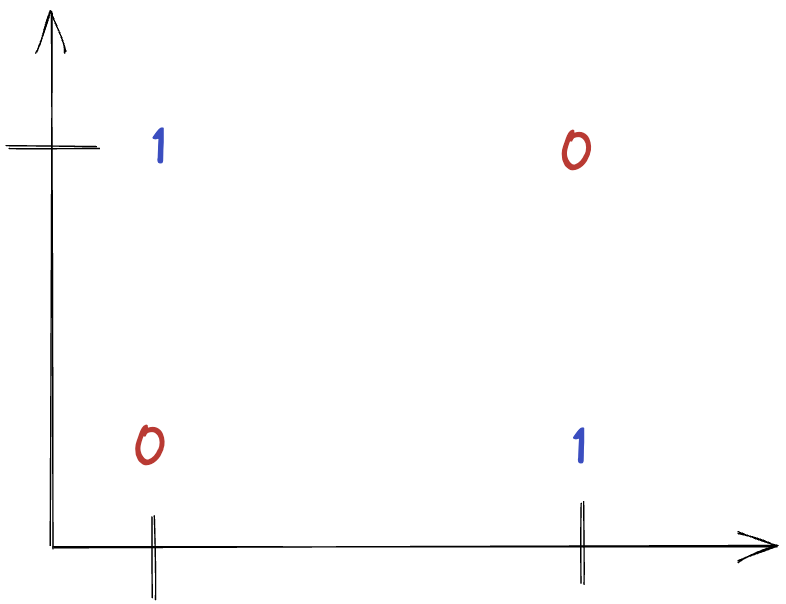
| label | ||
|---|---|---|
| 0 | 0 | -1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | -1 |
Can we find a two layer MLP to solve this problem?
Let , for the following derivations
MLP: where
Training Neural Networks
Steps:
- Collect / clean data and labels
- Specify model: select model class / architecture and loss function
- Train model: find the parameters of the model that minimizes the empirical loss on the training data
How to best find Hyperparameters
Your goal is always to make a generalizable model. Not to overfit.
- For training, there are typically two losses you should monitor
- Loss on the training data - how well the model will perform
- Loss on the validation data - how well the model generalizes
| Simple | Complex | |
|---|---|---|
| Low | Ok | Underfitting |
| Higher | Overfitting | Ok |